
Кластеризация ключевых фраз с помощью KeyAssort
02.09.2018
Опубликовано : 05-05-2017 | Рубрика : Программы | Автор : tekseo
Группировка запросов в семантическом ядре позволяет решать сразу несколько важнейших задач. При создании нового сайта она помогает продумать логическую структуру будущего веб-ресурса и разработать эффективный контент-план. Правильное распределение ключевых слов также значительно повышает конверсию, снижая процент отказов (посетитель будет находить именно те товары/сведения, в которых нуждался). Кроме того, четкое понимание, какие именно кеи должны присутствовать в одной публикации (чистой семантики оказывается мало) способствует быстрому выходу в ТОП даже в условиях высокой конкуренции. Наконец, кластеризация — отличный способ предупреждения коллизий, когда разные страницы одного ресурса конкурируют между собой в выдаче (так называемой каннибализации), провоцируя бессмысленный расход бюджета.
При всех преимуществах такого подхода, его практическое воплощение проблематично. Хотя современный рынок предлагает немало разнообразных сервисов, их активное использование выливается в непомерные траты. Для примера, возьмем достаточно популярный Rush Analytics. При кластеризации семантического ядра емкостью 50 000 запросов, вы потратите 300 долларов США, и это лишь на один-единственный проход. Любая ошибка при подготовке семантики и настройке параметров обойдется вам действительно дорого. Можно найти дешевле: за тот же объем SemParser возьмет порядка 12 тысяч руб. (около 200$), но даже это является неприемлемым для крупного проекта.
Долгое время я искал десктопную утилиту, которая могла бы послужить заменой онлайн-инструментов, при этом предлагая продвинутые возможности автоматической сортировки и последующей ручной обработки. И сегодня я бы хотел рассказать о, не побоюсь этого заявления, лучшем решении для кластеризации в русскоязычном сегменте Интернета — KeyAssort .
Плюсы программы для группировки запросов
Для затравки, начну обзор с краткого перечисления сильных сторон приложения:
1. Адекватная ценовая политика. По состоянию на май 2017 года, бессрочная лицензия на 1 компьютер стоит всего 1900 рублей, что для специализированного ПО подобного класса более чем демократично. При покупке дополнительных копий вы также получите скидку 20%; 2. Гибкое лицензирование. Если вы сделали апгрейд, или появилась необходимость переноса утилиты на другую машину, просто запросите реактивацию. Однако этой услугой можно воспользоваться не чаще 1 раза в месяц; 3. Честное демо. На официальном сайте выложена полнофункциональная демонстрационная версия KeyAssort. В ней нет каких-либо функциональных или временных ограничений, кроме заблокированного экспорта. Таким образом, перед оформлением заказа вы можете самостоятельно оценить программу; 4. Оптимизация. Даже на старом двухъядерном ноутбуке под управлением Windows XP кластеризация 3000 запросов длилась не более полуминуты; 5. Разделение процедуры сбора данных и обработки информации. В первого взгляда этот факт кажется мелочью, на практике же такой подход позволяет сэкономить баснословные суммы. Механизм работает так: вы загружаете список ключей, после чего запускаете сканирование поисковой выдачи. Результаты сохраняются в текущем проекте, дальнейшая кластеризация осуществляется уже на их основе, что исключает перерасход лимитов Yandex.XML; 6. Подробная справка. На сайте разработчиков имеется руководство пользователя и даже наглядные видеоуроки.Разумеется, абсолютно совершенный продукт создать нельзя, однако недостатки KeyAssort относительны. Например, хотя программа поддерживает всю актуальную линейку ОС Виндовс, начиная с народной “хрюши” и заканчивая ультрасовременной “десяткой”, версий под Mac OS или той же Ubuntu не существует. Так что маководам и линуксоидам придется использовать VirtualBox, или его аналог. Еще довольно странно ведут себя подсказки в меню:
К сожалению, отключать каждую вызванную подсказку приходится вручную — было бы куда удобнее, если бы предыдущее сообщение исчезало при вызове нового. Надеюсь, это учтут в будущих патчах.
Еще одна претензия заключается в довольно медленном обновлении уроков на сайте. Последняя версия КейАссорт обзавелась рядом важнейших функций, которые до сих пор не освещены в официальной документации. Но не беда — сейчас мы исправим это досадное упущение.
Работа по кластеризации ключевых слов
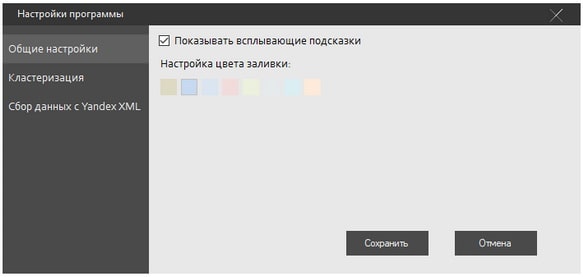
Прежде, чем создавать проект и проводить какие-либо манипуляции, необходимо должным образом настроить утилиту. Для этого отправляемся в “Сервис” —> “Настройки”. В первом разделе вы можете включить подсказки (рекомендуется для новичков), а также выбрать цвет фоновой заливки.
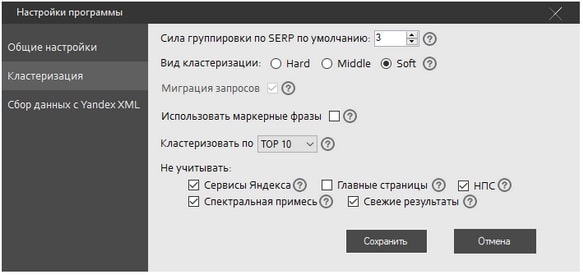
На рубрике “Кластеризация” остановимся более подробно, так как именно от этих параметров зависит эффективность сортировки ключевых слов:
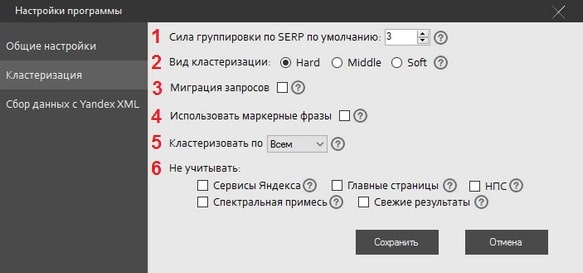
1. Сила группировки по SERP (от 0 до 100) — по сути мы определяем, насколько запросы должны быть похожи, технически же — указываем количество общих URL для образования группы. В режиме Hard (о том, что это такое, речь пойдет ниже) минимальным является показатель в 3 урла, Soft — 4-5. Для тематик с низким качеством выдачи и малой конкуренцией лучше установить 1 или 2.
2. Вид кластеризации: Hard, Middle, Soft
При выборе метода “Софт” главным запросом назначается самый частотный ключевик. Чтобы оказаться в одной с ним группе, другие ключи должны иметь некоторое число совпадающих с выбранным маркером адресов, при этом они могут вовсе не пересекаться между собой. Проиллюстрируем данную ситуацию:
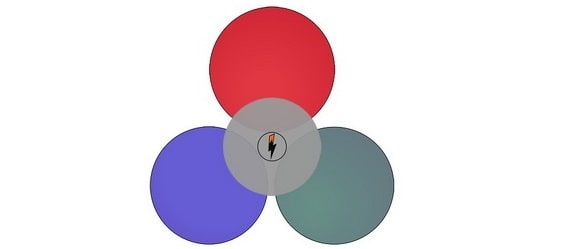
По завершении группировки запросов в семантическом ядре мы получаем малое количество групп довольно внушительного размера, а значит нам придется создавать меньше новых страниц. Такой подход актуален при работе с интернет-магазинами, статейниками, агрегаторами и любыми другими проектами с высоким трафиком, где на первый план выходит полнота охвата.
Напротив, “Хард” требует, чтобы у всех ключевых фраз присутствовал единый набор линков, в противном случае они будут определены в разные группы. Данное условие полностью исключает смысловую несовместимость запросов:
Метод применяется довольно редко, например при продвижении сайтов услуг по высокочастотникам. Дело в том, что в режиме “Hard” создается очень много групп маленького размера, которые включают явно похожие слова и могут быть объединены. Как следствие, значительно возрастает бюджет на контент.
“Миддл” же является этакой золотой серединой. В одну группу попадают все запросы, имеющие с маркером общие ссылки. При этом количество последних равно или превышает выбранный порог. Такой вариант используется, когда “мягкая” группировка семантического ядра отработала недостаточно хорошо, а жесткая привязка ключей неприемлема.
3. Миграция запросов — функция позволяет добиться более точной кластеризации, однако при этом увеличивается время обработки информации. Если фраза в уже сформированной выборке имеет более сильную связь с другим множеством ключей, то осуществляется ее перенос “на лету”.
4. Использовать маркерные фразы — галочку стоит проставить, если вы уже самостоятельно подобрали целевые фразы для определенных страниц продвигаемого веб-ресурса: именно они и станут маркерами.
5. Кластеризовать по — здесь указывается количество URL, которое будет собрано из выдачи. В числе доступных вариантов: “Все” и диапазон Топ 5 — 50 с шагом 5.
6. Не учитывать:
● Сервисы Яндекса — исключаются все собственные службы поисковика; ● Главные страницы — не принимаются во внимание все обнаруженные homepage; ● НПС — не учитываются результаты поиска, найденные по ссылке (то есть, ключевик присутствует в URL, но отсутствует в тексте самого документа); ● Спектральная примесь — игнорируется спектр (для большей точности рекомендую включить, так как это поможет избавиться от мусорных анкоров); ● Свежие результаты — пропускается “добыча” быстроботов (актуально, например, при работе с новостными порталами).Для большинства случаев подойдут следующие настройки:
Тем не менее, многое зависит от ниши продвигаемого проекта, уровне конкуренции, характера самих запросов и других факторов, так что для достижения оптимального результата придется поэкспериментировать.
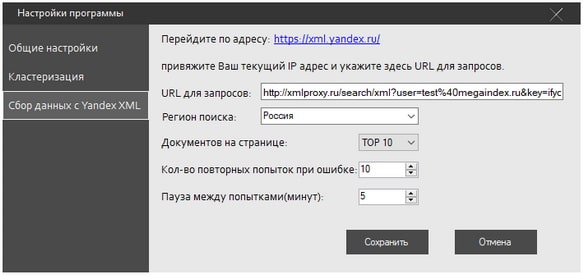
На последней вкладке, “Сбор данных с Yandex XML”, необходимо вписать в поле “URL для запросов” актуальную ссылку для вашего аккаунта, узнать которую можно здесь: https://xml.yandex.ru/settings/ . Кстати, адрес, указанный по умолчанию, дает возможность делать 100 бесплатных запросов в сутки — используя его, вы можете протестировать работу онлайн-сервиса xmlproxy.ru , который торгует запросами к Яндексу по цене 5 рублей за 1000 обращений. Альтернативное решение — покупка XML-лимитов на специализированных биржах. Впрочем, это уже тема для отдельной статьи.
Здесь также определяется желаемый регион поиска и число документов на странице. Такие параметры, как количество повторов при ошибке и пауза между попытками в большинстве случаев стоит оставить без изменений:
Приступаем к кластеризации фраз
После настройки КейАссорт, можно заняться делом. Отправляемся в “Файл” —> “Создать новый проект”, и указываем наиболее подходящее место на диске. Теперь необходимо загрузить предварительно подготовленное семантическое ядро. Для этого идем в “Файл” —> “Импорт” и выбираем один из четырех вариантов:
1. Файл с параметрами. Обеспечивает загрузку XLSX-документа, содержащего, помимо ключей, любые другие сведения.
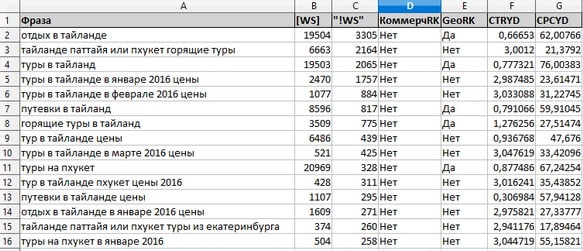
2. С данными о поисковой выдаче. Дает возможность перекластеризовать XLSX-выгрузку результатов, полученную в других программах и сервисах.
3. Список фраз. Позволяет загрузить txt-файл, содержащий перечень анкоров. Каждый из них должен начинаться с маленькой буквы и с новой строки, как показано на скриншоте ниже.

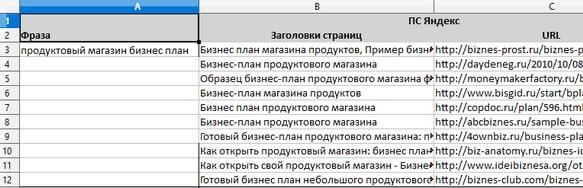
4. Ручное добавление. Позволяет скопировать ключевики напрямую из буфера обмена, либо вбить вручную в специальном окне:
Отдельно отмечу, что программа для группировки запросов KeyAssort обладает достаточно продвинутой системой управления импортом Excel-таблиц, и поддерживает перенос связанных данных. Как это работает? Выбрав соответствующий метод и указав нужный документ, вы увидите следующее окно:
Убедитесь, что галочка установлена, и нажмите “Продолжить”. В следующем шаге вы сможете явно указать, в каком именно столбце находятся сами ключевики. В нашем случае это будет “Фразы”
Наконец, последний шаг — выбор информации, которая будет перенесена:
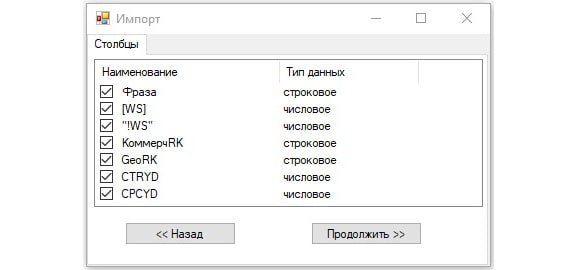
Результат импорта будет выглядеть следующим образом:
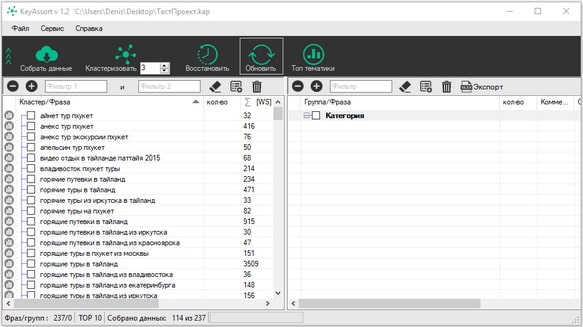
Таким образом, вам будет легче ориентироваться и оценивать качество кластеризации семантического ядра. Теперь можно смело нажимать на иконку “Собрать данные” и ожидать завершения процесса.
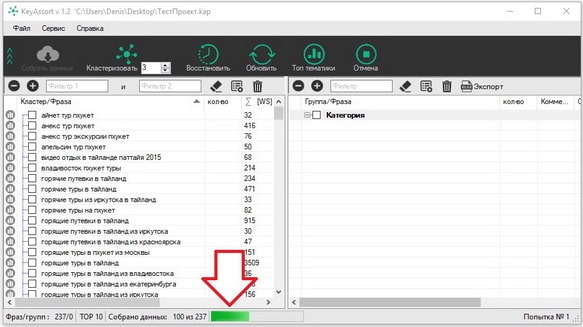
Затем нажимаем на “Кластеризовать”, чтобы запустить непосредственно группировку семантического ядра. Обратите внимание, что показатель силы кластеризации, который мы устанавливали в настройках, можно менять и непосредственно на приборной панели. Для чего это нужно? Все просто. По завершении процедуры, вы получите некоторое количество групп ключевых фраз.
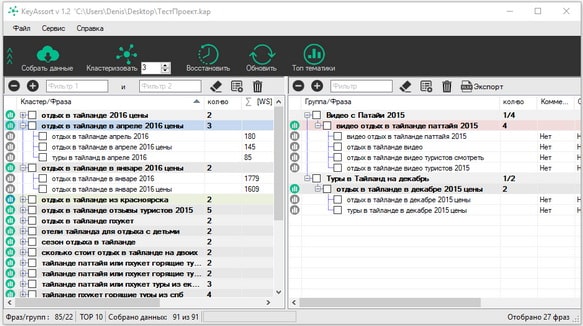
Если какая-то выборка окажется слишком обширной — проставьте галочку в соответствующем чекбоксе, увеличьте параметр силы и вновь запустите процесс!
Теперь можно приступать к ручной сортировке. Для этих целей предусмотрено правое окно. Строго говоря, я уже переместил туда пару групп путем обычного перетаскивания мышью. В программе есть возможность создания собственных категорий с произвольными названиями, что очень удобно для планирования структуры веб-проектов. Контекстное меню вдобавок позволяет выделять требуемые позиции разным цветом.
Еще одной фишкой является наличие двойного фильтра с поддержкой логических операторов “И” и “ИЛИ” (переключаются простым кликом). Разберемся, как они работают на примере ключевых слов “туры” и “Пхукет”. Выставив значение “И”, мы получаем все фразы, содержащие оба кея в указанных словоформах.
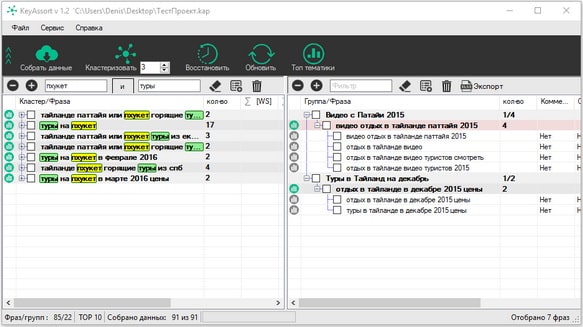
“ИЛИ”, напротив, покажет как словосочетания, содержащие оба ключевика, так и те, кто имеет лишь один из них. Важная особенность: поиск осуществляется именно по группам. Если в кластере есть хотя бы одно вхождение искомых лексем, он обязательно окажется в подборке, что хорошо видно на представленной ниже картинке (выделено красным).
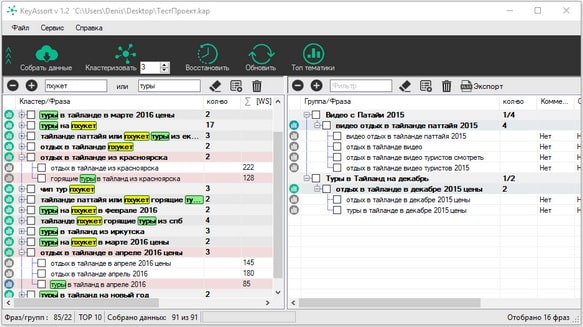
Обратите внимание также на зеленые кружочки слева от кластеризованных ключевых фраз. Щелкнув по ним, вы сможете просмотреть список ссылок, полученных при сканировании выдачи по целевому запросу.
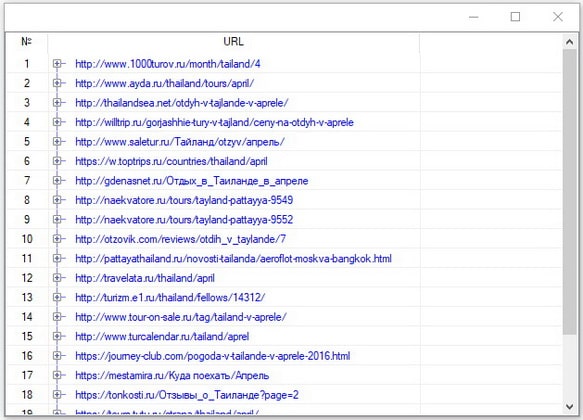
Таким образом, кроме всего прочего, вы получаете в свое распоряжение перечень конкурентов, который придется кстати в ходе разработки дальнейшей маркетинговой стратегии. Что же касается экспорта, то выгрузка в Эксель осуществляется довольно интересным способом: формируется сразу две вкладки, на первой из которых запросы представлены в виде единого списка, а на второй организованы в структуру, что обеспечивает дополнительное удобство.
В заключении я бы хотел указать на еще один нюанс — наличие обратной связи с разработчиками. Считаю этот аспект не менее важным, чем общее качество, ведь даже самый талантливый программист не сможет создать достойный продукт, забыв о реальных потребностях его потребителей. На портале КейАссорт предусмотрен специальный раздел “Предложить свою функцию в программу”, где каждый покупатель может оставить собственные пожелания. И это действительно работает: на момент написания статьи уже ведется работа над добавлением возможности парсинга Google, причем идея была озвучена одним из клиентов.
Подытожим
При богатом функционале, описанное решение отличает весьма низкая стоимость — фактически, затраты на покупку лицензии отобьются уже после первого запуска программы для кластеризации ключевых слов, и это несмотря на необходимость оплаты XML-лимитов (что, в любом случае, обойдется куда дешевле, нежели услуги онлайн-сервисов). Кроме того, приложение характеризуется высоким быстродействием и стабильностью (лично я не встретил ни одного бага или вылета), а все данные хранятся на вашем компьютере, что также пригодится при работе с семантикой — вероятность потери наработок из-за нестабильного интернет-соединения сводится к нулю. С учетом перечисленного, рекомендую KeySort всем, кто профессионально занимается поисковым продвижением и нуждается в надежном и эффективном инструменте автоматизации типовых задач.